从3.5.2升级到3.7.2后,同样的策略公式,同样的数据源和时间范围,新旧版本的策略研究的年化收益差距巨大,请问你们修改什么了?优化应该是程序本身算法优化,但不能影响用户自己编写的公式策略的研究结果吧。不能让用户的公式为了你们的算法调整。
一 请问何时能处理结果?
二 如果短期不能给出答复,那么用户是否应该升级到3.7.2版本?我担心你们升级不仅影响策略研究,如果也影响策略实盘,那就麻烦大了,所以在没有给出答复前,我不敢升级到3.7.2版本。
本来不想多说了,但是感觉您还有有怨气,抱怨我未公布源码给客服,浪费彼此时间来处理在您看来本来微不足道的问题。但是换一个角度。从3.5.3到3.7.2,即便把回溯数默认值降低为了提高回测的效率,降低运算的压力,但是这个压力在用户的机器,又不在开拓者的服务器上。从结果来看,我宁愿让用户抱怨效率太低,找出问题原因后,降低回溯数默认值。也不愿意让小白用户由于回溯数默认设置过低,错误用了高量运算导致策略研究结果错误,再根据错误去修正策略,错上加错。一个是效率低,一个是结果错误,取轻取重。作为公司运营者,应该清楚分量。何况我用的都是非常低级的lowd,cloesd的函数,没什么高深技术。这些问题,就算我不提供源代码,在版本升级时,公司测试部就应该测出来的,提交给领导做决策,是要效率,还是准确度。我没有提交代码的义务,您也没有必须回答的义务。如果不是公司有回复率的考勤绩效考虑,从我的角度,您即便不回复,我也不会有任何意见。但是我还是感谢开拓者公司,你们能从专业角度高效解决问题,及时找到回溯数过低的原因。
回溯限制是为了节省内存空间,提高运行效率
你定义了一个序列的对象,内存就会分配一段空间用来存放这个序列对象的所有值。你需要回溯的范围越大,这个分配的空间就越大。如果你平时需要回溯的范围可能就不超过三位数,那么默认系统给五位数的存放空间就浪费了。如果你的程序算法非常复杂,体量和算力要求都非常高,那这个就是一种很好的优化手段。这也是很多深度用户的需求。
另外,问题是否有深度这个都无所谓,并不是说简单的问题就不会回答,而是你面对帮助的态度显得太过于遮遮掩掩,不太想提供一些关键信息用于分析。那么有一说一,如果你一直不肯提供要求的关键信息,以后的问题我也就不回答了。医院里的医生最讨厌的,就是病人跑过来看病,问什么都不回答,反倒自己给自己确诊了。自己既然这么懂还看什么医生呢?
按照你说的,最大回溯范围都不超过几百根,那么这个回溯设置应该是对你无效的,如果你改了设置反而差距小了,这个就非常匪夷所思了。按照你现在提供的这些完全没有参考意义的信息来看,我完全无法分析出原因。至于你说的现象,上面的截图我已经给出了我的证据,两个版本的测试报告完全没有差异。如果你不能给出更明确的论点指出我证据的不足之处,我就不再继续关注了。
第一条回复就已经告诉你了,找客服平台,把工作区文件发给客服,或者让客服远程看你所谓的“问题”。
绕了这么一大圈,纯粹浪费时间
按照你的提醒,我设置了SetBackBarMaxCount,果然好多了,两次测试差别非常小。
没有提技术含量高的问题,主要是因为能力有限,很多高深的理论理解不了,自然也问不出问题。其实新版本的90%以上的功能基本都用不到。大道至简,只是借用开拓者平台实现自己设计的简单思路。也不是高盈利模型,只是做到勉强不亏,但也不愿意外示,跟加密无关,保护心态而已。另外我没有用10000根bar的均线,最多只用到几百根。
UB=NthCon( *****);
DB=NthCon( **** );
UB2=UB[UB+1]+UB+1;
DB2=DB[DB+1]+DB+1;
KDA1 = NthCon( ***UB**DB2 );
KKA1 = NthCon( ***DB***DB2 );
我用NthCon比较多,里面嵌套了Series变量,最多10级。但是NthCon外面再嵌套NthCon,可能嵌套了5层。不知道和这个有没有关系,另外我觉得这个是平台,应该可以应对各种极端的测试,只要遵循编程规范,能编译通过,就是合规的策略,不能因为版本的更新迭代,导致公式失效或者回测混乱。SetBackBarMaxCount 我查了一下,是设置回溯bar数,我现在还没完全理解为啥把这个设置大会消除我的公式的新旧版本的策略研究结果。按理说,那你们把这个默认值设置成一个比较大的值,为啥不可?这样满足大多数的用户的需求。而不是默认设置为一个比较小的值,需要我调整为非常大才行?我用的数据不过才20万条。我现在设置的回溯默认值是100万,也许设置再小点也可以,但还没测。难道设置大了会影响大部分策略的结果,所以你们把默认值设置的非常小?对这个函数的默认值设置不是很理解。
上面是两个版本同样设置的系统公式测试,没有发现你说的差异巨大的问题,官网没有1352版下载 用的1351
你的问题我印象里一直很难回答,倒不是你一直在提技术含量很高的问题,而是你一直不太配合。上面说过了,可能要分析你具体的使用设置和公式代码才能得到结论,可是你拒绝掉了。
那么我只好随便复现一下,复现不出你说的问题,你说这该怎么解决呢?
我能猜到的一个可能性,就是序列类型的回溯范围缩小了,所以你如果有一些很奇葩的指标比如要计算10000根bar的均线或者类似的函数计算,那可能会造成指标值算错
SetBackBarMaxCount 你可以通过这个函数来调整回溯范围,比你最大的回溯参数大一点就行了。
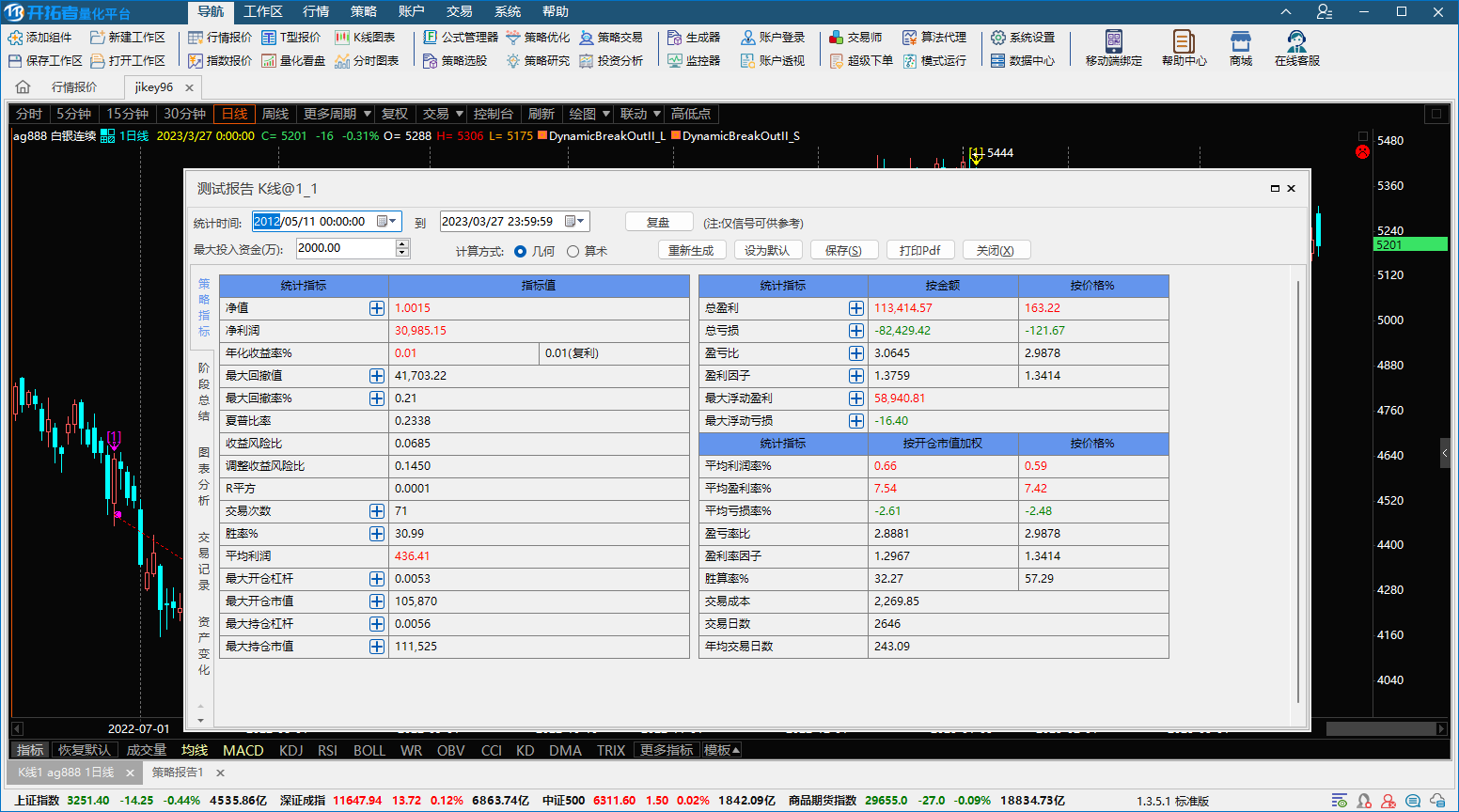
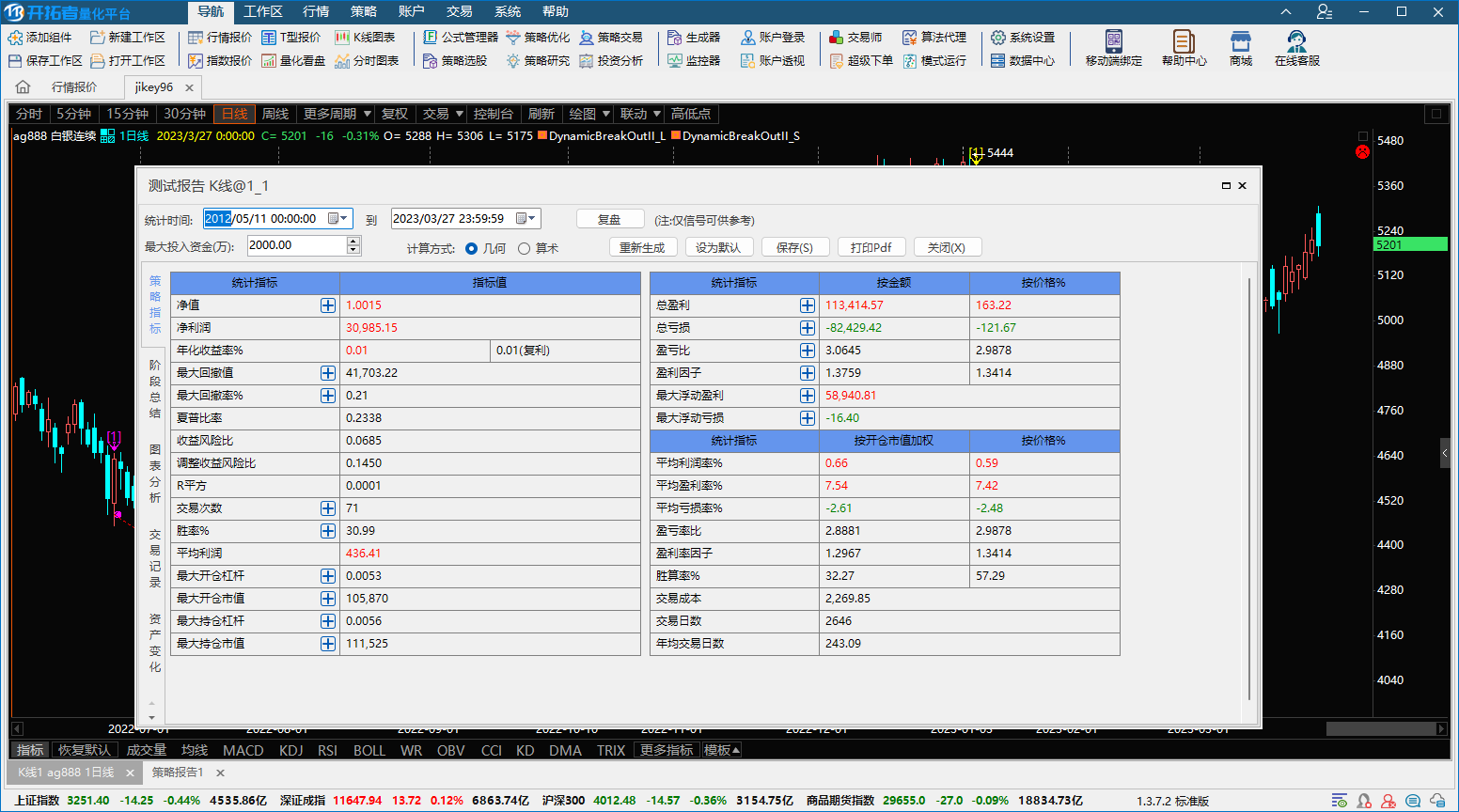
我反复测试了多次,已经简化到只用一个品种,相关配置也是反复比较,还是在新旧2分版本上的策略研究出来的结果有明显差异,我没提交给客服,因为这个和我的公式应该关系不大。所以我想确认一下,你们的新版本,比如用经典的海归算法,对单个品种,在新旧版本上,固定周期内,得出的研究结果,是否一致?你们的测试工程师肯定有相关的测试报告。如果一致,那就是我的公式问题或者环境配置问题。如果不一致,那就是普遍问题,那么你们优化的本地模拟处理,为何会导致策略优化的结果不一致呢?
我会按照你们的建议重新检查我的两次环境设置是否有差异,并重新测试。
但能否回答我2个问题
1 在升级说明里,你们提到对本地模拟处理做了优化。请问,在你们的测试报告里,同样的公式,同样的数据源环境,是否会因为本次的本地模拟处理优化,而会对策略研究的结果导致细微差异,还是完全不变?
2 我的2次次数,都是把老版本里上次测试的,比如品种集合,公式,都是导出的方式保存为文件,然后在新版本里导入,重新进行测试,是否存在老版本的导出,到导入新版本,会有数据格式的不兼容导致后面的一系列问题?有没有这种可能?
建议你把具体的证据提交给客服,你这样说很难排除不是你哪里设置不一样的问题。
建议把工作区导出,附带公式,可以无源码。我们会通过两个版本比较复现你的结论