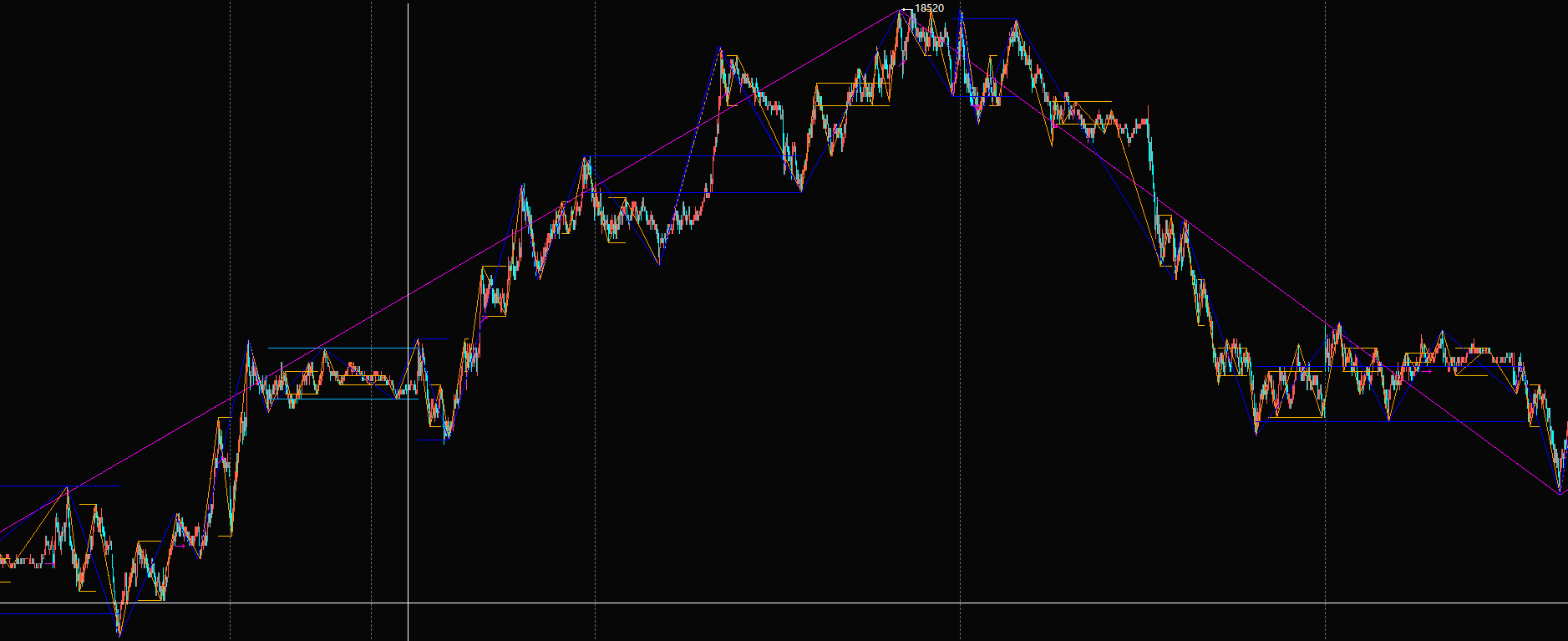
公式在k线上有绘图,并且屏幕上k线显示数量很多的情况下,放大和缩小的动作执行非常慢。缩小后出现长竖线。观察资源监视器,放大和缩小执行过程中,cpu的十几个核里,只有2~3个核有参与工作的迹象,并且平均利用率低于50%。请问官方,是否能想办法增加tb的多核使用率和提高单核利用率?
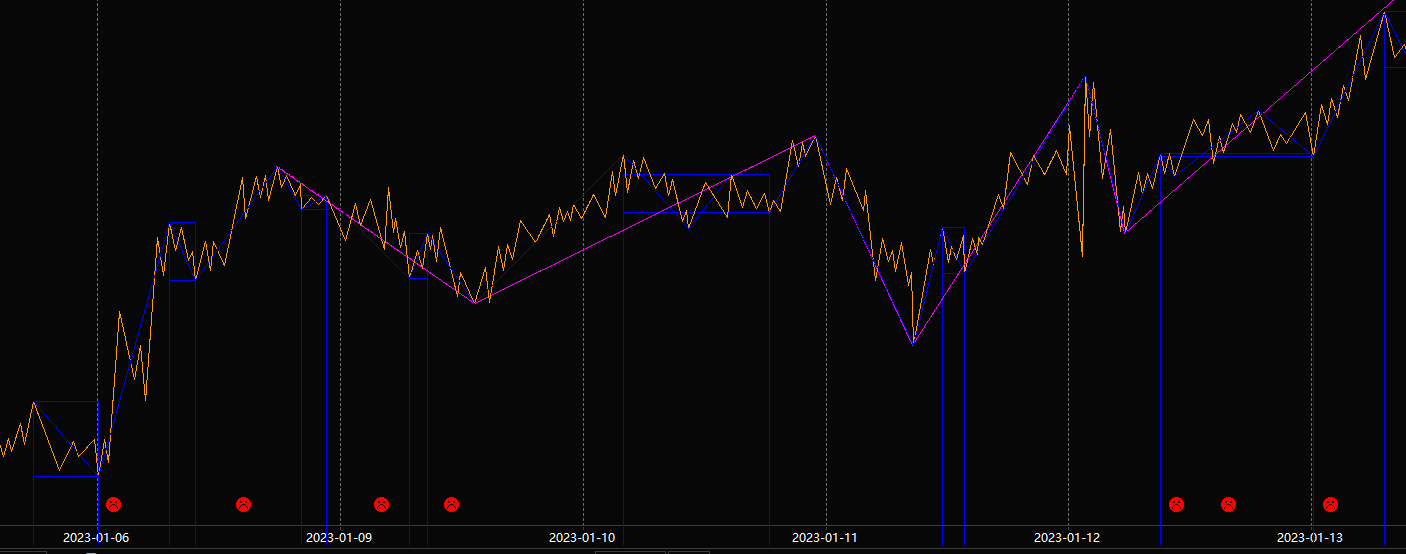
谢谢各位关注!目前可以直接从笔递归到线段、1级走势,后面完全可以递归2级走势、3级走势了,图形缩放、拖拽问题基本解决。感谢大家一直的关注!
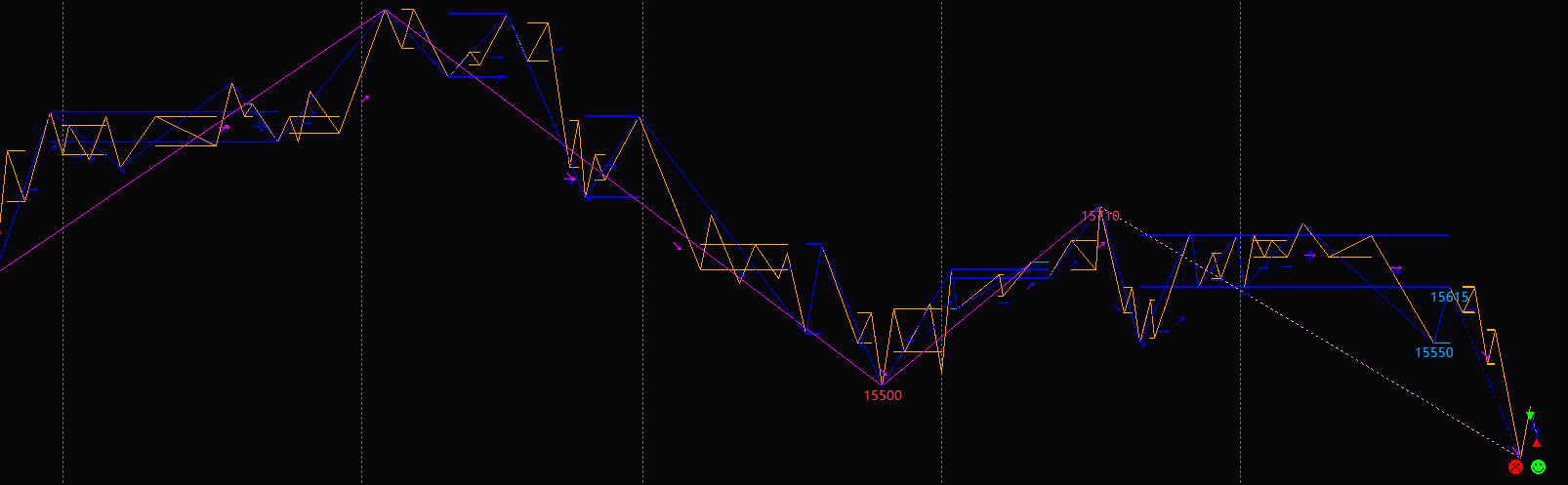
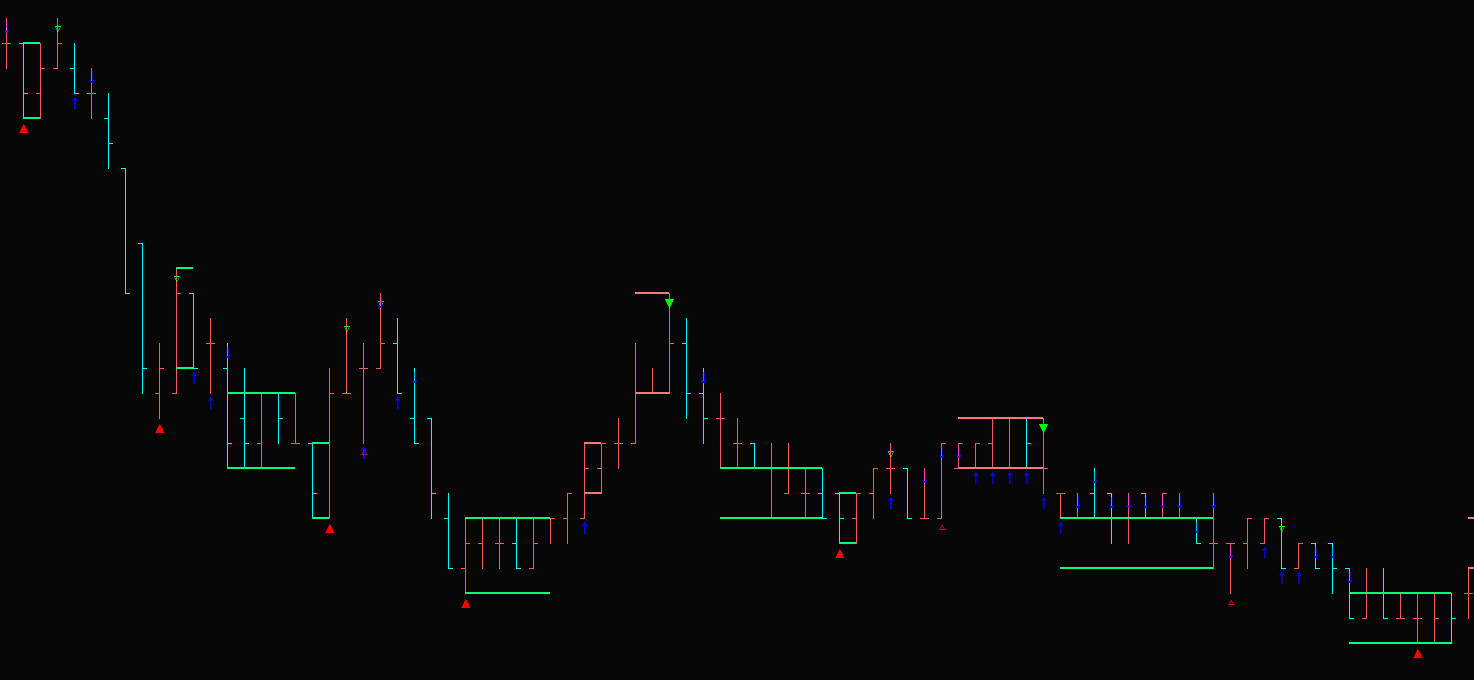
这里展示了K线包含的全过程。空心三角是原始分型,实心三角是落定分型。经过笔的规则,去除不符合笔要求的落定分型,就形成了笔。仔细琢磨吧。
向大家汇报优化的情况:
1.把整个模块整合在一个公式内,比分模块(函数)分层次(主次函数)的分布式架构,图示(同周期、同时间长度)缩放拖动要顺畅些,但编译速度慢,仅限于线段递归,再向上递归,程序崩溃。
2.分布式架构优化后,比优化前稍稍有所改善的是两个方面:主程序编译速度快;向上递归可以实现。问题是:图示缩放拖动卡顿现象十分严重。我把图示上的所有图形输出全部关闭,还是这个现象。
初步结论:软件目前很难承载较大的模型运行。如果采取每一个递归一个独立公式,写入基础数据,通过读取低级别基础数据,再向上一层层递归。通过多公式同时运行,实时读取。这样的分布式架构,可能解决这些问题。
但愿听到专家建议!
@rtmb888215 可以选择在大周期上操作,可以过滤掉很多小级别,另外请教一下,基础K线处理时,吞没线是一直往前吞,直到吞不下为止,还是只吞前面那一根,我之前只用三根判断,只吞前一根来写的
包含关系,前后都要包含的。
后面有具体图例。
在一个周期里获取顶底分型,不断向上递归收敛,不跨周期,是不是会快一些
我就是这样做的。
建议你把计算拆成两部分, 如果用的时tbquant 建议你在策略交易单元里把你要输出的这些笔或者中枢位置的点实时计算写基础数据,然后另外再写个公式,读取基础数据并在k线显示即可解决卡顿问题。如果你用的时智大领峰,大批量计算可以通过新建页面的策略运行里运行写基础数据,然后通过另一个公式读基础数据并显示。
你的卡顿问题即使提高了内存和cpu效率, 再你切换品种时,因为要大批量多周期重新订阅及计算也会再卡顿的。所以分布式处理,计算和展示能有效解决你的需求,甚至计算你都可以分布式,一个策略单元运行1分钟中枢计算并写基础数据,另一个策略单元用5分钟读取1分钟中枢信息合成5分钟,并再写入基础数据,15分钟再读5分钟中枢数据,等等
写入基础数据的方法,原先也考虑过,担心实时的效率问题,后来没有进行。现在主要将各个层级走势拆分成函数,然后调用。问题还是比较大!
基础数据是可以用 SubscribeDic 实时订阅的, 只要你硬盘读写速度够快就行, 这样,计算和显示就分离了, 显示时就不需要调用过多资源,你可以试试,
谢谢指点!我目前正在优化,尽力提高运行效率!然后再分布式读写基础数据。最后也只能走这条路!
谢谢关注!目前正在优化。昨天梳理参数传递,删除了可有可无的参数。今天考虑分型、笔的函数,调到主程序内部,成为内函数,看看能不能提升效率。
关闭笔中枢,再向上递归,图表还是运行缓慢
我已经实现了缠论的递归,中枢不用竖线,但是,拖动、缩放图表时,卡顿现象十分严重,有时10~20秒才能动一动。请问专家,能不能解决这个缺陷。
缠论实现量化,真的不容易。我已经经过了五年多的努力了,才能基本实现。恳请软件专家能改进改进图表运行速度的问题!!拜托拜托!
我还要向上递归2个级别走势。我担心,图表会运行不起来了!