问题:函数NormalCumDensityArray-数组的正态分布累计概率密度,和函数NormalDensityArray-数组的正态分布概率密度,两个函数计算结果为什么对应不上?
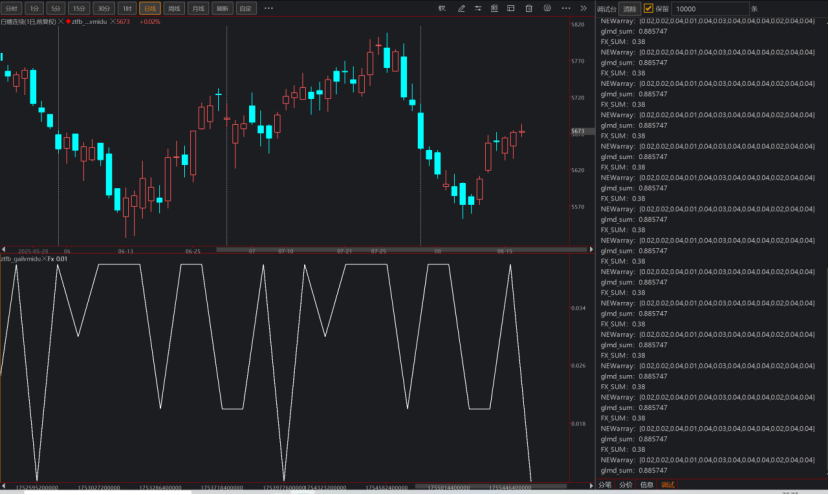
对于一维数组:arr = [86.38, 62.10, 72.88, 88.75, 72.75, 82.55, 71.04, 69.09, 74.93, 86.43, 78.40, 73.19, 57.33];用NormalCumDensityArray函数计算结果是0.885747,而单独对于数组每一个数值用NormalDensityArray函数算法进行独立运算再累积和的时候,得到的结果是0.38。
请问老师:为什么结果会有差异?
程序代码如附件或下面拷贝代码。运行结果见如下截图。
Params
Vars
Numeric TowPiRoot(2.506628275);//sqrt(2*Pi)
Numeric Var1;
Numeric Var2;
Numeric Fx;
Array<Numeric> arr;
Series<Array<Numeric>> Fxarray;
Series<Numeric> i;
Plot pen1;
Events
OnInit()
{
pen1.figure(1);
}
OnBar(ArrayRef<Integer> indexs)
{
arr = [86.38, 62.10, 72.88, 88.75, 72.75, 82.55, 71.04, 69.09, 74.93, 86.43, 78.40, 73.19, 57.33];//构建一个13个数值的一维数组。
Var1 = AverageArray(arr);//求数组均值。
Var2 = StandardDevArray(arr,1);//求数组标准差。
If(Var2 >0)
{
Fx=Round(1/(TowPiRoot*Var2)*Exp(-1*Sqr(arr[i] - Var1)/(2*Sqr(Var2))),2);//用NormalDensityArray函数的内部计算公式求数组每一个数值的概率密度值,保留两位小数。
pen1.line("Fx", Fx);//附图作图。
ArrayInsert(Fxarray, i, Fx);//计算结果放入一维数组。
i=i+1;
if(i==12)//对数组arr进行循环语句计算。
{
Array<Numeric> NEWarray;
ArraySwap(Fxarray,NEWarray);//将序列型数组转换成数值型数组。
Numeric FX_SUM = SummationArray(NEWarray);//求数组概率密度的和。SummationArray必须使用数值型数组,不能使用序列型数组,所以要用上一条语句转换,转换后原来的数组内容就清空了。那么下面的语句就要用新的数组了。
print("FX_SUM:" + text(FX_SUM));//FX_SUM:0.38。单独计算的数组每一个数值概率密度的累加值是0.38.
print("NEWarray:" + textarray(NEWarray));//数组每一个数值的概率密度值:NEWarray:[0.02,0.02,0.04,0.01,0.04,0.03,0.04,0.04,0.04,0.02,0.04,0.04]
Numeric glmd_sum = NormalCumDensityArray(arr);//直接用函数求数组的正态分布累计概率密度,结果是:glmd_sum:0.885747
print("glmd_sum:" + text(glmd_sum));
i = 0;
ArrayClear(Fxarray);
}
}Else
{
Fx= -1;
}
}
正态分布累积函数在线计算器,吊打Excel https://remarkable-babka-d8efba.netlify.app
我想起来了
概率密度是计算连续的概率分布的
密度相加是没意义的
因为跟离散的概率分布 不是一个东西
没仔细看帖子
连续概率分布的密度是需要积分的
要不说想听数学课呢

刘老师:对于数组,属于离散概率密度,是不是不能进行其中每一个数值单独计算后的概率密度相加?因为我尝试了,结果不一样,那么对于数组的概率密度函数,从公式看,只计算了数组第一个数值,那么它有什么作用呢?
离散型求的是频次,就是单个元素在样本空间里出现的次数。
你想求什么?
离散数据是没有概率密度的概念的
系统公式的数组的概率密度是有强的前提假设的,假设这组数据服从正态分布
正态分布是连续分布,其上任何一点的概率都是0,所以才有了概率密度的概念
你把概率密度当成概率去加减,是没有意义的
你这也不需要教啊
这是概率书前10%的内容....
后面就很头大了....
从联合分布开始 后面的贝叶斯 协方差 极限定理 矩阵 伯努利....
都是云山雾罩...我想认识它 它说跟我不熟😬😬😬
因为该函数的定义所得结果是概率密度,所以我想看看求出来的结果代表了什么含义,感觉和什么内容都对应不上。
所以想知道TBQ的概率密度函数得到的结果有什么用途,这个数据是不是可以应用。
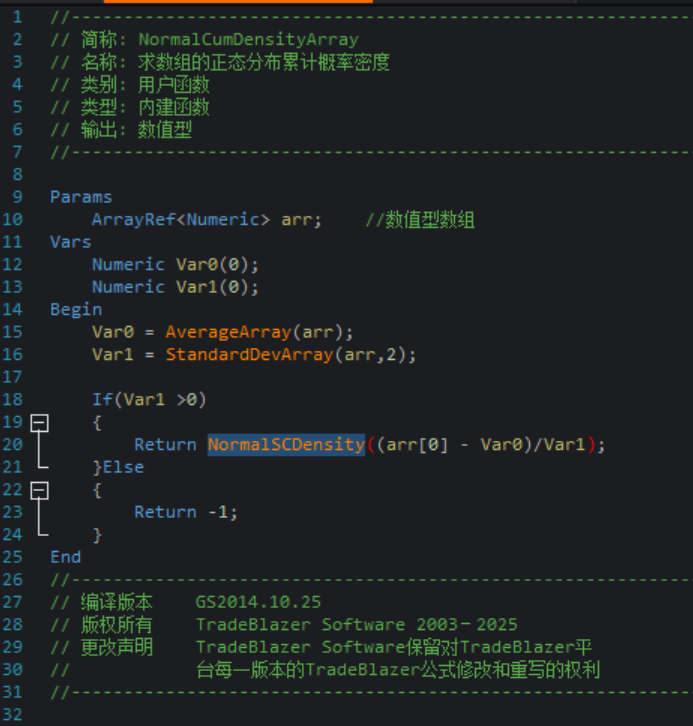
看了一下这个数组算法,这个是假定数组元素服从某个正态分布,求第一个元素的概率
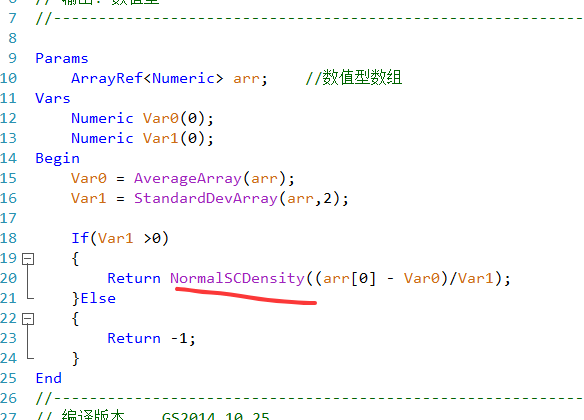

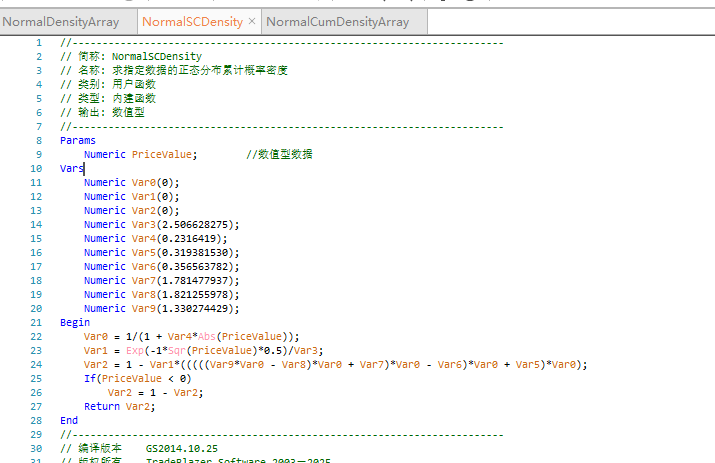
有源码的
老师:我是想反向推导出结果看看各个函数的关联关系,推导的结果不一致,不知道哪里出错了。
源代码已经有了,你可以从运行逻辑上推理